Lessons Learned Using Flyway DB with Distributed Version Control
Recently our team introduced Flyway for automating schema changes to our database. Along the way, we learned a few interesting lessons about using a schema migration tool in a team heavily bought into a distributed version control.
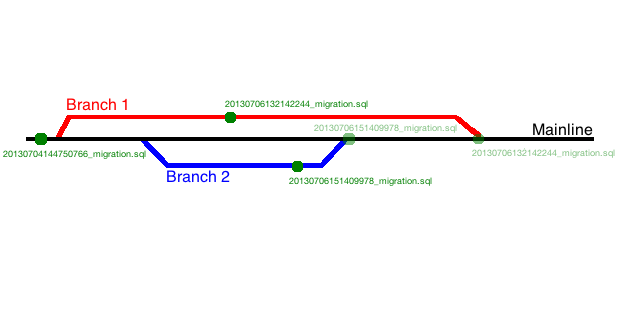
Our team uses Git for source control which gives us the ability to easily create branches used only by a few developers. Like most teams, our workflow consists of creating a branch from the mainline branch of code, implementing and testing a new feature inside of that branch, and then merging that branch back into the mainline for shipping.
This can cause a bit of havoc with the default configuration of Flyway, but it can be easily worked around using the tips below.
Prefix your migrations with timestamps rather than integers
By default, most migration frameworks choose to prefix the individual migrations with an integer, as in the example below. When the framework encounters migrations not yet applied to the current database, it starts with the first migration whose prefix isn't present in the database and begins applying them in ascending order.
1__add_customers_table.sql
2__add_email_address_column_to_customers_table.sql
3__add_orders_table_with_reference_to_customer_table.sql
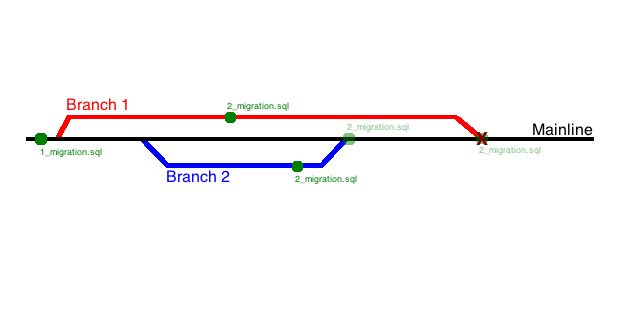
This works great when everyone is on the same branch of code. However, once members of the team begin working on their own branches, the likelihood of a prefix collision increases dramatically.
But, if you choose to prefix your migrations using timestamps rather than integers, then the likelihood of a collision virtually disappears, even across branches. For example, using a pattern such as yyyyMMddHHmmssSSS the migrations above now look like...
20130704144750766__add_customers_table.sql
20130706132142244__add_email_address_column_to_customers_table.sql
20130706151409978__add_orders_table_with_reference_to_customer_table.sql
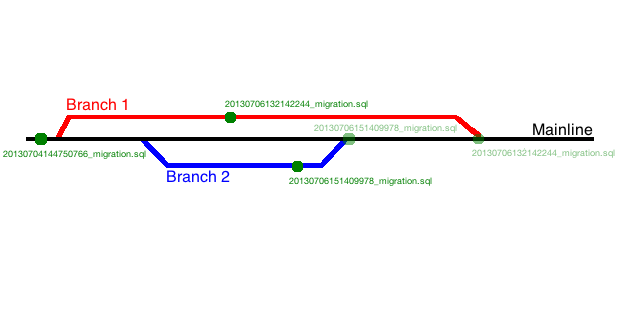
The timestamp pattern above is precise down to the millisecond. While a highly precise timestamp can lead to hard to read prefixes, the more precise your prefix then the less likely a collision will be.
For best results, you'll want to automate the creation of this timestamp so all members of your team are using a consistent format. To get you started, I've added Gists of both the Ant task and the Groovy task that we use to prefix new migrations.
In addition, note that Flyway also treats timestamp prefixes as integers. This means that if you originally began working with Flyway using integers then you can still switch to timestamps at any point. Since the timestamps are just very large integers, the first timestamp prefixed migration will simply be applied after the last integer prefixed migration.
Enable out-of-order migrations
Now that we're using prefixes to timestamp our migrations we can rest assured that we won't have any collisions when our branches are merged back into the mainline. However, what about your teammates who stayed on the mainline? Once your changes are merged back in they'll need to apply your migration to their databases but they'll already have higher prefixed migrations.
By default, Flyway will not apply migrations older than the latest migration already applied to the database. That means in our last example your team members will not be able to apply your latest migration.
To allow this, you'll need to enable out of order migrations with Flyway. This is as easy as setting the Out of Order value to true in whichever API you're using to drive Flyway.
Create idempotent migrations



In a perfect world, each migration will only be run once against each database.In a perfect world, that is.In actuality, there will be cases where you'll need to re-run migrations against the same database. Often this will be due to a failed migration somewhere along the line, causing you to have to retrace your steps of successful migrations before to get the database back in a working state. When this happens, it's incredibly helpful for the migration to be written in an idempotent manner. If you're not familiar with idempotence, it's simply a very fancy term describing an operation that can be performed multiple times without additional effects.Let's take the migration below, which adds a column to a table, as an example... Assuming that your database already contained a table customers, this migration will successfully add the email_address column to it.
However, what would happen if you ran this migration a second time against that same database? Since the email_address column now already exists in the customers table, you would receive and error along the lines of this...Now imagine troubleshooting this situation if it occurs in a much more complex migration script, particularly if that script is only one of multiple scripts currently being applied to the database.
We can avoid this issue by making our migrations idempotent...or able to be applied multiple times without side effects.
This is done by checking the the state of the database before making any change to it, and only applying the change if necessary. In the example above, changing the script to be idempotent might yield something like this...This is introduces a fair amount of noise into our script, but at a high level we're simply enclosing our ALTER statement in an IF statement that first checks the database's information schema tables to determine whether that column exists for that table for that database. If the column already exists then the script simply returns, otherwise it is added to the table. This allows us to run the same script multiple times against the same database without issue.
Note that this is actually a bit tricker if you're using MySQL. Since MySQL doesn't allow IF statements outside of stored procedures the statement above actually won't work as a stand alone script. In order to create idempotent migrations in MySQL it's actually necessary to enclose each migration in a stored procedure, execute the stored procedure against the database, and then drop the stored procedure at the end. I've added a Gist here that demonstrates this method for MySQL.
Wrapping up
While I've used Flyway, MySQL, and Git in my examples here, none of this is actually specific to these technologies. In fact, you're likely to encounter the same types of issues when introducing database migrations in any environment using a distributed version control system. Luckily, the techniques above should be supported in any mature migration framework and can save you a lot of potential pain and headaches.